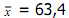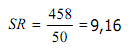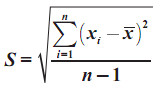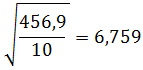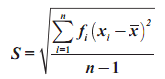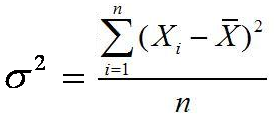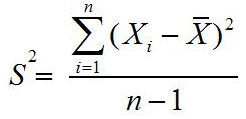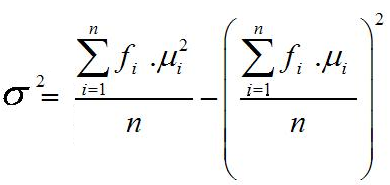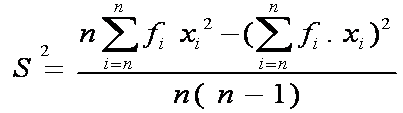STATISTIKA BAB VI. Distribusi Normal, Distribusi T, dan Distribusi F
STATISTIKA
BAB VI. DISTRIBUSI NORMAL, DISTRIBUSI T, dan DISTRIBUSI F
DISTRIBUSI NORMAL
Distribusi normal adalah distribusi dari variabel acak kontinu.
Kadang-kadang distribusi normal disebut juga dengan distribusi Gauss.
Distribusi ini merupakan distribusi yang paling penting dan paling
banyak digunakan di bidang statistika.
Fungsi densitas distribusi normal diperoleh dengan persamaan sebagai berikut:

dimana
π = 3,1416
e = 2,7183
µ = rata-rata
σ = simpangan baku
Persamaan di atas bila dihitung dan diplot pada grafik akan terlihat seperti pada Gambar 1 berikut:

Gambar 1. kurva distribusi normal umum
Sifat-sifat penting distribusi normal adalah sebagai berikut:
1. Grafiknya selalu berada di atas sumbu x
2. Bentuknya simetris pada x = µ
3. Mempunyai satu buah modus, yaitu pada x = µ
4. Luas grafiknya sama dengan satu unit persegi, dengan rincian
a. Kira-kira 68% luasnya berada di antara daerah µ – σ dan µ + σ
b. Kira-kira 95% luasnya berada di antara daerah µ – 2σ dan µ + 2σ
c. Kira-kira 99% luasnya berada di antara daerah µ – 3σ dan µ + 3σ
Membuat kurva normal umum bukanlah suatu pekerjaan yang mudah. Lihat
saja rumus untuk mencari fungsi densitasnya (nilai pada sumbu Y) begitu
rumit. Oleh karena itu, orang tidak banyak menggunakannya.
Orang lebih banyak menggunakan DISTIBUSI NORMAL BAKU. Kurva
distribusi normal baku diperoleh dari distribusi normal umum dengan cara
transformasi nilai x menjadi nilai z, dengan formula sbb:
Kurva distribusi normal baku disajikan pada Gambar 2 berikut ini.


Gambar 2. Kurva distribusi normal baku
Kurva distribusi normal baku lebih sederhana dibanding kurva normal
umum. Pada kurva distribusi normal baku, nilai µ = 0 dan nilai σ=1,
sehingga terlihat lebih menyenangkan. Namun, sifat-sifatnya persis sama
dengan sifat-sifat distribusi normal umum.
Untuk keperluan praktis, para ahli statistika telah menyusun Tabel
distribusi normal baku dan tabel tersebut dapat ditemukan hampir di
semua buku teks Statistika. Tabel distribusi normal bakui disebut juga
dengan Tabel Z dan dapat digunakan untuk mencari peluang di bawah kurva
normal secara umum, asal saja nilai µ dan σ diketahui. Sebagai catatan
nilai µ dan σ dapat diganti masing-masing dengan nilai  dan S.
dan S.
Distribusi t
Distribusi t merupakan salah satu pengembangan dari Distribusi z. Secara
prinsip penggunaan Distribusi t digunakan untuk membandingkan rata-rata
dari dua sampel. Rata-rata dua sampel tersebut dibandingkan untuk
mengetahui apakah dua data tersebut mempunyai beda. Distribusi biasanya
digunakan untuk data yang banyak sampelnya kurang dari sama dengan 30.
t di definisikan sebagai berikut:

Dari definisi nilai t di atas, ada beberapa nilai yang perlu kita ketahui:

sehingga inputan data di atas sebaiknya anda tahu.
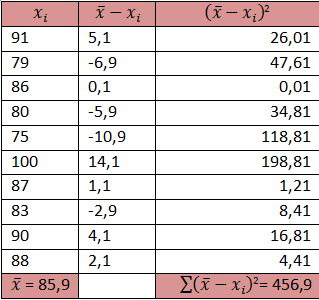
Contoh ada nilai siswa sebagai berikut:
Nilai
|
66
|
40
|
75
|
64
|
65
|
71
|
66
|
81
|
65
|
50
|
Apakah nilai data tersebut rata-ratanya sama dengan data yang lain yang rata-ratanya 60?
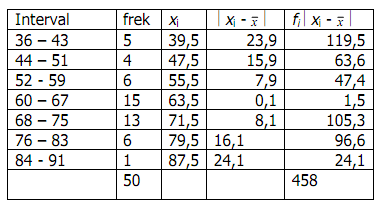
Dari data di atas diperoleh nilai sebagai berikut:

Misalkan taraf signifikansinya 0.05, nilai derajat kebebasan data tersebut dk = 10 - 1 = 9. Dari tabel distribusi t didapatkan :

Sedangkan nilai t hitung bisa diperoleh dari :

Dari nilai tersebut diperoleh

Kesimpulannya data diatas tidak berbeda signifikan dengan data yang rata-rata populasinya 60.
Distribusi F (ANOVA)
ANOVA kepanjangan dari Analysis of Variance. Distribusi yang ditemukan oleh seorang ahli statistika bernama R.A Fisher pada tahun 1920. Distribusi F (ANOVA) adalah prosedur statistika untuk menghitung apakah rata-rata hitung drai 3 populasi atau lebih sama atau tidak. Distribusi ini digunakan untuk menguji rata-rata dari tiga atau lebih populasi sekaligus untuk menentukan apakah rata-rata itu sama atau tidak.
Distribusi F (ANOVA) terbagi menjadi 2 klasifikasi:
- Klasifikasi satu arah
2. Klasifikasi dua arah
Klasifikasi dua arah adalah suatu pengamatan yang didasarkan pada dua kriteria seperti varietas dan jenis pupuk.suatu pengamatan dapat diklasifikasikan menurut dua criteria dengan menyusun data tersebut menjadi baris dan kolom, kolom menyatakan kriterika klasifikasi yang satu sedangkan baris menyatakan criteria klasifikasi yang lainnya.
SUMBER :
GOOGLE
http://adzaniahdinda.wordpress.com/2013/04/07/distribusi-f-anova/
http://adzaniahdinda.wordpress.com/2013/04/07/distribusi-f-anova/
http://hatta2stat.wordpress.com/category/distribusi-normal-2/
http://sofwan-mat.blogspot.com/2013/06/uji-dengan-distribusi-t.html